HOMOLOGY MODELLING
Homology modeling, also known as comparative modeling of protein, refers to constructing an atomic-resolution model of the "target" protein from its amino acid sequence and an experimental three-dimensional structure of a related homologous protein (the "template").
Using the FASTA Sequence that we obtained from UniProtKB we now use the same to build a 3-D model of our target protein.
We use the followiwng server to build a 3-D model:
SWISS-MODEL
The FASTA Sequence is uploaded in the Start a New Modelling Project window and then Build Model
tab is selected.
This gives us the following output:
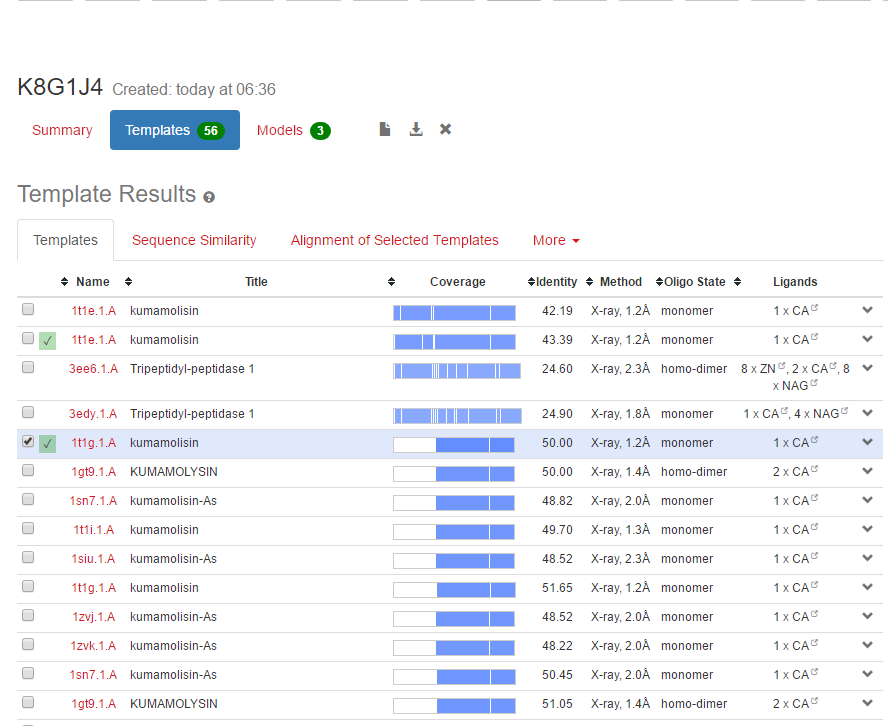
The best choice in the list of 56 templates is the 1t1g.1.A as it has the best sequence identity with 50% identity which is above the "Twiligt region" of 30% for modelling.
Although it was tough to decide on which would be a better model as we can see that 1t1g.1.A has less coverage with higher identity, whereas 1t1e.1.A has higher percentage of coverage but lesser identity of 42.39%. I have chose to continue to build a model with 1t1g.1.A.
By clicking the drop down arrow in the right, we will get the alignment of the target sequence with the template as follows:
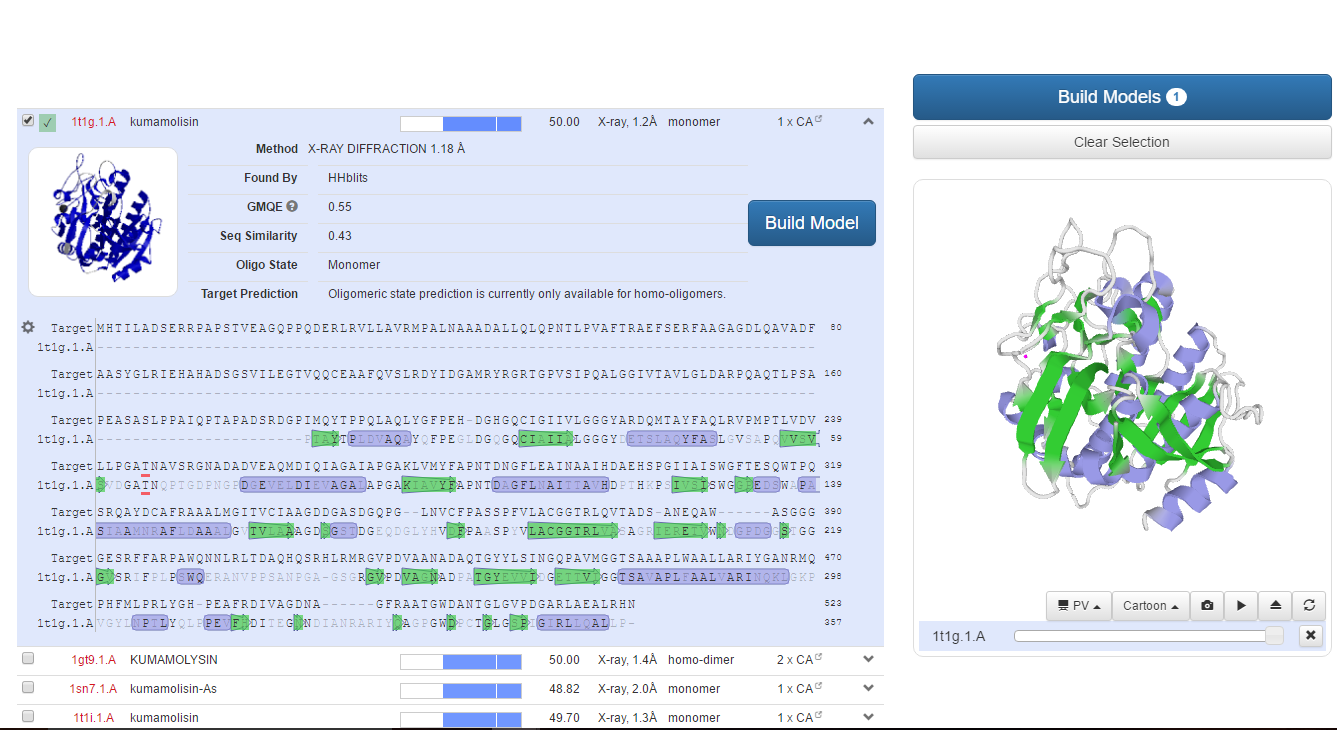
Figure shows the sequence alignment of the template with the target protein
We now proceed to look at the model. First we need to analyze the quality of our template model. To analyze the quality of model we look at the QMEAN value which is -1.14 thus when comapred with the 1t1e.1.A QMEAN value of -2.40 we can be at a better situation to say that we can continue with the 1t1g.1.A model. The QMEAN (Benkert et al.) is a composite scoring function for the estimation of the global and local model quality. Also by looking at the Local Quality image we can see that the low similarity values are detected at the begining (this is due to the coverage gap) whereas as we move forward we can see that the similarity value is on the higher side and hence the template is more similar to the target model.
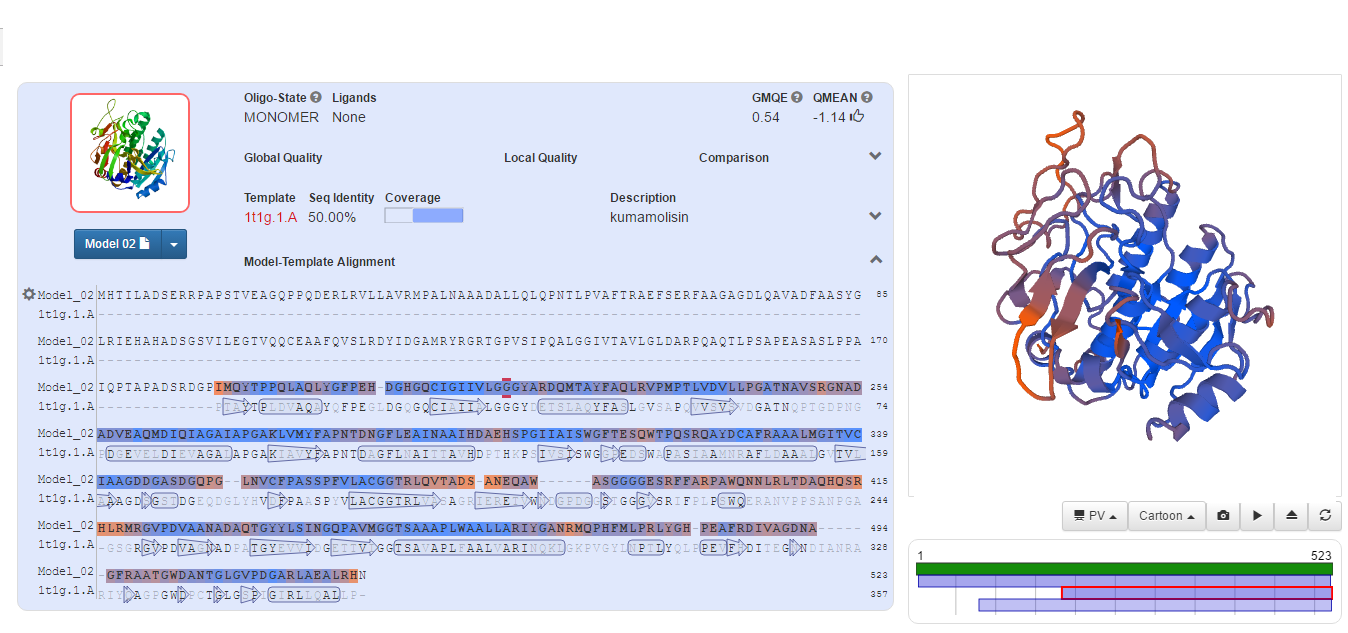
Figure shows the model of 1t1g.1.A
The complete result set for our model can be viewed here.